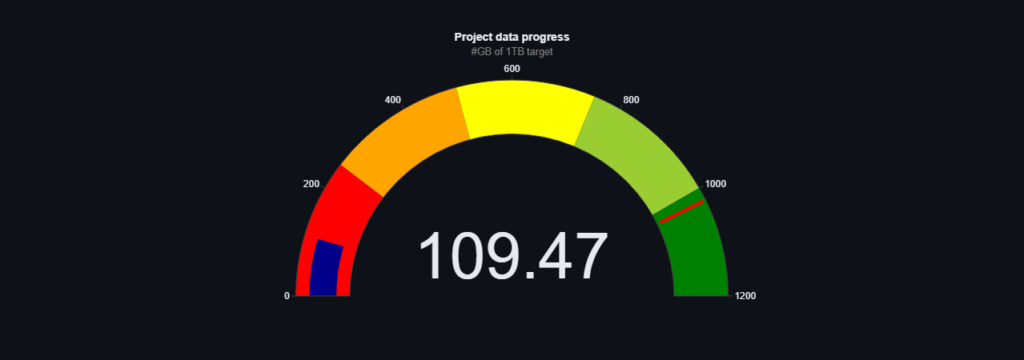
Po miesiącach ciężkiej pracy i niekończących się rozmów możemy powiedzieć że dołożyliśmy kolejną dużą cegiełkę ku realizacji naszego celu. Osiągnęliśmy ponad 100 GB danych tekstowych! A wśród nich są takie źródła z polskojęzycznej Wikipedii, prace naukowe czy powieści. Co Wy na to? Jakie jeszcze dane, z jakich źródeł chcielibyście aby się znalazły w pierwszym polskim GPT? Zapraszamy do wglądu.